





























Tus fotos de Instagram a cambio de una IA perfecta: la nueva y polémica propuesta de Meta
13 de junio de 2024 Por Ana Perez y Jimena de Diego
Hace unos días, Meta anunció que empezará a utilizar el contenido publicado en Facebook e Instagram para entrenar su modelo de inteligencia artificial a partir del próximo 26 de junio. Una noticia que no ha gustado entre los usuarios, quienes temen que su privacidad se vea comprometida y han hecho un llamamiento para activar su derecho de oposición.
La compañía ya anunció el lanzamiento de Meta AI (aún no disponible en España) en mayo, un ChatGPT propio que permitirá a los usuarios crear contenido a través de la IA generativa, contar con un asistente virtual siempre disponible o “conversar” con 28 personajes diferentes, entre muchas otras cosas. Un lanzamiento con el que buscan ampliar las funcionalidades de la ‘app’ y mejorar la experiencia de los usuarios a través de esta tecnología.
Ante la inminente incorporación de la IA en su sistema, Meta ya ha trazado un plan para luchar contra la desinformación y los deepfakes: un sistema de etiquetado automático de los posts generados por inteligencia artificial. Esta funcionalidad emularía a la ya implementada por TikTok a principios de año, que resulta muy necesaria en una red social donde la IA generativa es parte clave de la generación de contenido (sobre todo, en los audios y los filtros).
Sabiendo que Meta parece estar poniendo mucho cuidado para que la IA se incorpore de forma segura en Facebook e Instagram, nos parece inevitable la pregunta: ¿por qué ahora anuncian que su modelo de IA se nutrirá de los datos de los usuarios, sabiendo la polémica que esto puede generar?
Las redes sociales necesitan entrenar sus mecanismos de IA
Para entenderlo, debemos partir de la base de que las herramientas de IA son modelos estadísticos, predictivos y generativos, por lo que necesitan aprender patrones y tendencias para desarrollarse. De esta manera, sin una base de datos consolidada y diversa no serían capaces de brindar resultados acertados y útiles.
Por ello, todas las plataformas que hacen uso de la inteligencia artificial generativa necesitan cantidades ingentes de datos para perfeccionar sus modelos, por lo que este aspecto no es exclusivo de las compañías propietarias de redes sociales.
En un principio, el hecho de entrenar los mecanismos de IA de las redes sociales haciendo uso de los datos de los usuarios podría derivar en aspectos a priori beneficiosos, como la oferta de una experiencia de usuario más personalizada, la creación de nuevas funcionalidades y servicios adaptados a las necesidades…
No obstante, ante el revuelo ocasionado por Meta en su reciente propuesta, varias personas han podido pensar en primera instancia que este hecho podría traducirse en el uso literal de su información y fotos (incluyendo sus rostros y cuerpos) para la creación de contenido. En términos estrictos, el uso de la IA no conlleva la copia directa de una foto u obra, sino en aprender a generar nuevo contenido a partir de ella.
Las críticas al gigante de las redes sociales también han sido ocasionadas por la dificultad a la hora de denegar este permiso y poner la “responsabilidad” en el usuario, ya que es este el que activamente tiene que buscar el apartado para oponerse en sus plataformas, formular su oposición al uso de sus datos y esperar a que esta se le conceda.
De hecho, Noyb (None of Your Business), organización austriaca que vela por la defensa de la privacidad, ha presentado quejas formales ante las autoridades de protección de datos de once países europeos, entre los que se encuentra España, argumentando que Meta estaría violando la normativa europea de protección de datos (GDPR) al no solicitar un consentimiento explícito de los usuarios para el uso de sus datos.
A esto se suma la respuesta de los usuarios en RRSS que, por lo general, ha sido bastante crítica. En las últimas semanas, internet se ha llenado de tutoriales sobre cómo notificar a Meta la oposición ante el uso de los datos personales, e incluso de protestas sobre la situación.
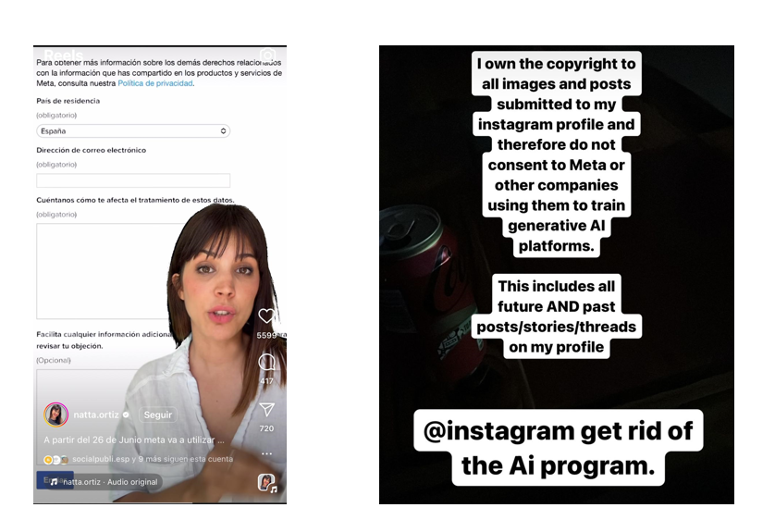
Esta tesitura también ha alarmado a muchos miembros de la comunidad artística, que se han mostrado en contra de que sus obras sean utilizadas para entrenar a los modelos de IA y que incluso están abandonando ya las redes de Meta. Estos objetan que no han dado su beneplácito para que sus creaciones se utilicen con este fin y muestran su temor a que puedan ser utilizadas sin los créditos ni la compensación adecuada.
No obstante, el impacto potencial de entrenar a la IA con la información de los propios usuarios transciende más allá de los derechos de la privacidad y de las obras de autor. Muchos expertos señalan el riesgo de que este tipo de herramientas puedan utilizar sus bases de datos para generar contenido que influya en la opinión pública y en la conducta de los usuarios. Al señalar esto, es difícil no recordar el escándalo ocurrido con Cambridge Analytica, que ya demostró lo vulnerable que puede ser la información en el plano digital y cómo esta puede explotarse con fines políticos y poco éticos.
Una decisión desacertada en un mundo que valora mucho la privacidad
Está claro que la IA necesita aprender de nosotros para poder funcionar. Necesita de personas que la entrenen para poder afinar todo lo posible su lenguaje y ofrecernos resultados lo más acordes posibles a lo que esperamos. Cada vez que usamos ChatGPT, o cualquier herramienta de inteligencia artificial generativa, debemos ser conscientes de que la estamos entrenando a través de nuestros prompts.
Sin embargo, hay que tener en cuenta que, para el usuario medio, introducir un comando en una herramienta puede resultarle muy diferente a ceder fotografías, vídeos o textos personales publicados en sus perfiles sociales. Y es que, a pesar de que IA generativa se está integrando poco a poco en nuestras vidas, estamos en una era en la que la privacidad cada vez se valora más, y las redes sociales son conscientes de ello (de hecho, precisamente esto fue lo que motivó a Meta a lanzar funcionalidades como ‘mejores amigos’ en Instagram).
En este sentido, creemos que el proceso que ha seguido Meta debería haber sido más transparente, explícito y sencillo. Una opción podría haber sido seguir el procedimiento inverso: que la cesión de datos esté inhabilitada por defecto y los usuarios puedan activar el consentimiento si así lo desean. Es inevitable que las compañías busquen entrenar a sus propios algoritmos, pero el cómo se hace es igual o más importante.



